GPT-Image-2: OpenAIの最新画像モデルがもたらす真の変化
PicFixer.ai リサーチチーム | 2026年4月
GPT-Image-2: OpenAIの最新画像モデルがもたらす真の変化

更新日: 2026-04-23
TL;DR —
gpt-image-2はOpenAIの現在のフラッグシップ画像モデルです。ここで注目すべきは「より美しい画像が作れるようになった」ことではありません。画像生成が、単なるムードボードの素材から、実際にユーザーへ提供できる本番環境レベルのビジュアル出力へと、ついに一線を越えたということです。
概要
gpt-image-2は単なるマイナーアップデートではありません。OpenAIが現在、画像生成や編集を伴うあらゆる新規作業のデフォルトとして位置づけているモデルです。中でも以下の4つのアップグレードが特に重要です:
- 信頼性の高いテキスト描画 — ポスター、インフォグラフィック、コミックのコマ、多言語プロモーションアート。
- 安定した編集 — 参照画像、キャラクターの一貫性、マスク編集、反復的なブラッシュアップ。
- 構造化されたレイアウト — 単一のヒーロー画像だけでなく、インフォグラフィック、図解、マルチパネルのコミック。
- 世界知識に基づくフォトリアリズム — 現実のコンテキストに配置された、本物のように見える出力。
SaaS、デザインツール、コンテンツプラットフォーム、Eコマースストア、ブランディングワークフローなど、編集可能な画像出力を必要とするあらゆるものを構築している場合、これは以前のモデルからの大きな進歩となります。
実際のところ何なのか
OpenAIは2026年4月21日にChatGPT Images 2.0をローンチしました。これは社内で**gpt-image-2**と呼ばれる次世代画像モデルです。その位置づけは明確です:
- 今後のデフォルトのGPT Imageモデル
- テキストからの画像生成(Text-to-image)と画像編集を1つのモデルで実現
- テキストと画像の両方の入力に対応
- 画像を出力
- フォーカス:高品質な生成、信頼性の高い編集、強力な指示追従性、複雑なレイアウト、画像内テキスト、フォトリアリズム、そして世界知識
実際に何が新しいのか

1. テキストからの画像生成(Text-to-image)
基本となる機能です。しかし、gpt-image-2のポイントは「絵が描ける」ことではなく、コントロール可能な描画であることです。OpenAIのドキュメントでは、幅広い世界知識に基づいた強力な指示追従性とコンテキスト認識について説明されています。
実際には、以下のような用途に適しています:
- ブランドのキービジュアル、バナー、OGP画像
- プロモーションポスター
- 記事のイラスト
- UIコンセプトアート
- キャラクターデザインシート
- 説明用イラスト
- Eコマースおよびマーケティングアセット
2. 画像編集
ここに真の進歩が表れています。ドキュメントでは、以下の2つの一般的なパターンにおける編集パフォーマンスが繰り返し強調されています:
- 画像全体の編集 — 画像を入力し、プロンプトでスタイル、素材、構図、またはコンテンツの変更を指示する
- マスク編集 — 他のすべてを保持したまま、選択した領域のみを変更する
真に役立つようになること:
- 参照画像ベースのバリエーション作成
- 局所的な再描画
- 顔やキャラクターの一貫性
- ブランドアセットのバッチ調整
- Eコマース:商品、背景、小道具の差し替え
- ゼロから再生成するのではなく、既存のアートワークを反復的に改善する
3. 画像内テキストとタイポグラフィ
これが最大のブレイクスルーです。OpenAIのプロンプトガイドでは、鮮明な文字、一貫したレイアウト、強いコントラストを備えた信頼性の高いテキスト描画が特に言及されています。
これにより前提が変わります。「AI画像はテキストを扱えない」というのは、これまでムードボードと完成したアセットを隔てる明確な境界線でした。gpt-image-2により、以下のものが突如としてスコープに入ってきます:
- イベントポスター
- インフォグラフィック
- 多言語プロモーションアート
- メニュー、表紙、フライヤー、ステッカー
- セリフ入りのコミックのコマ
- 教育用の図解やフローチャート
- ソーシャルメディアのテンプレート
4. 構造化されたマルチパネルコンテンツ
ドキュメントでは、その機能が以下に拡張されることが明記されています:
- インフォグラフィック
- 図解
- マルチパネルの構図
言い換えれば、もはや単なる「1枚の美しい画像」ではありません。構造化されたビジュアル出力を扱えるようになっており、コンテンツ、教育、またはマーケティング自動化プロダクトを構築するすべての人にとって大きな意味を持ちます。
5. スタイルの制御と転送
プロンプトガイドでは以下が強調されています:
- 正確なスタイル制御
- 最小限のプロンプトでのスタイル転送
以下の用途に役立ちます:
- 統一されたブランドビジュアル
- トーンが一貫した画像シリーズ
- 参照画像からのスタイル転送
- イラスト、コミック、ピクセルアート、写真、ポスタースタイルの切り替え
- 複数のシーンにわたる一貫したキャラクター
6. 世界知識とシーンの理解
システムカードでは、世界知識、指示追従性、および高密度なテキスト描画における大幅な向上が強調されています。これは以下の点で重要です:
- リアルなプロダクトプレイスメント
- 旅行、食品、小売のマーケティング
- 業界特有の正確さを備えたコンセプトアート
- 現実世界のコンテキストに基づいた商業ビジュアル
実際のプロダクトでどのように活用されるか
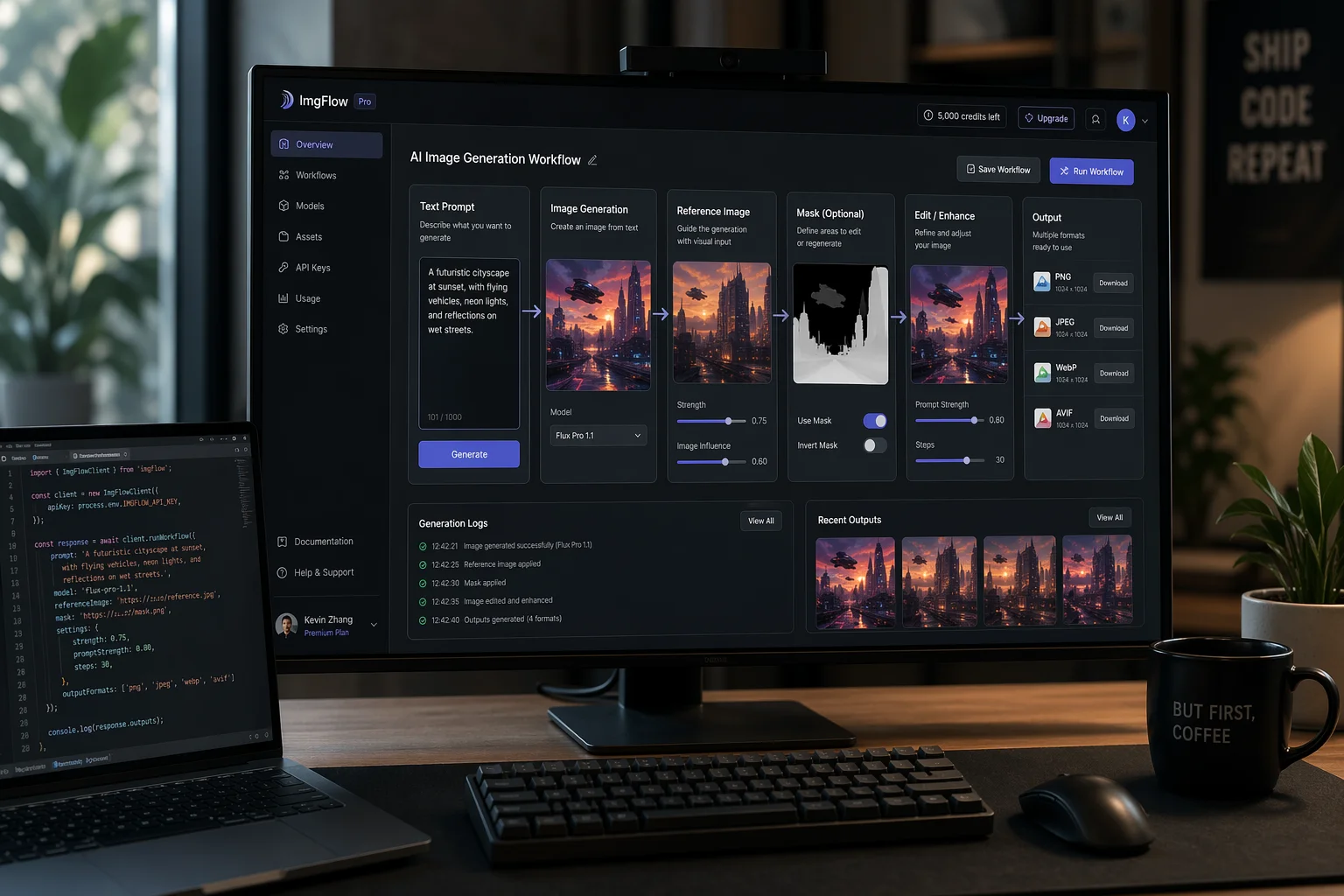
カタログスペック上の機能と、モデルが実際のユーザー向けワークフローに耐えうるかどうかは別の問題です。私たちが最近PicFixerでリリースした2つのツールは、この世代のモデルがもたらしたブレイクスルーによってのみ実現可能となりました。どちらも、古い画像モデルでは実質的に提供不可能なものでした。
Manga Translator
漫画のページの翻訳は、実際には翻訳の問題ではなく、テキスト描画の問題です。以前のAI画像モデルでは、日本語を英語に置き換えながら元のレイアウト、吹き出しの形状、コミックの美学を維持することはおろか、コマの中にきれいに組版されたテキストを書き込むことすらできませんでした。
gpt-image-2を使用すると、以下のことが可能になります:
- 吹き出し内のテキストを検出して置換する
- コマの構図と周囲のアートを保持する
- タイポグラフィをコミックの視覚言語に合わせる
- 単一のワークフローで複数のターゲット言語をサポートする
前世代の出力は、文字が潰れたり、歪んだり、かろうじて読める程度のものでした。この世代になって初めて、実際に読める結果が得られるようになりました。
お試しください → picfixer.ai/tools/manga-translator
AI Interior Design
1枚の写真から部屋を再設計することは、古いモデルでは根本的にうまくできないことでした。不可能な形状をハルシネーション(幻覚)として生成したり、窓やドアのレイアウトを壊したり、現実とは無関係なありきたりな「AIっぽい」家具を生成したりしていました。
gpt-image-2の忠実度の高い参照処理、世界知識、フォトリアリズムの組み合わせにより、以下のことが可能になります:
- 部屋の実際の構造を保持する
- 空間をそのまま保ちながらスタイル(北欧風、インダストリアル、ジャパンディ、ミッドセンチュリー)を変更する
- 実際に購入できそうなリアルな家具を生成する
- 1枚の写真から複数のデザインの方向性を反復的に試す
お試しください → picfixer.ai/tools/ai-interior-design
どちらのツールも、同じ根本的な変化の上に成り立っています。AI画像モデルはもはやムードボードジェネレーターではありません。本番環境のコンポーネントになりつつあるのです。
最も価値を発揮する領域
gpt-image-2が明らかに優位性を持つ8つのプロダクトカテゴリー:
- AIポスターおよびマーケティングアセットの生成
- 記事のイラストとインフォグラフィック
- Eコマース商品の編集とシーンのバリエーション作成
- ブランドビジュアルアセットの生成
- 複数画像間で一貫性のあるキャラクターデザイン
- 参照画像ベースのクリエイティブ編集
- 教育用の図解、フローチャート、解説ビジュアル
- マルチターンの対話型デザインアシスタント
ワークフローに以下のニーズのいずれかがある場合、そのメリットはさらに大きくなります:
- 画像内のテキスト
- 多言語出力
- 局所的な編集
- 一貫したキャラクターやオブジェクト
- 複数回の反復(イテレーション)
- 単なるインスピレーション用の静止画ではない、本番環境レベルの出力
筆者の見解
一言で要約するなら:
gpt-image-2は、「AI画像モデル」から「本番環境のパイプラインに組み込める画像生成・編集モデル」へと明確に進化しました。
その価値は、個々の画像がより印象的に見えることではありません。以下の点にあります:
- 初回試行での成功率が高い
- 編集ワークフローがリリースできるほど安定している
- テキストとレイアウトがついに機能するようになった
- デモだけでなく、実際のプロダクトに組み込める
- 反復的でマルチステップのワークフローが実際に意味を持つようになった
画像が単なるマーケティングの装飾ではなく、実際の出力となるプロダクトを構築しているすべての人にとって、この世代はAI画像生成が単なる目新しいものではなく、基盤として構築できるビジュアルエンジンのように感じられ始める転換点です。上記の2つのツールは小さな証明にすぎません。1世代前のモデルでは到底実現不可能だったカテゴリーが、今では提供可能になっているのです。