GPT-Image-2:OpenAI 最新图像模型究竟带来了哪些改变
作者:PicFixer.ai 研发团队 | 2026 年 4 月
GPT-Image-2:OpenAI 最新图像模型究竟带来了哪些改变

更新时间:2026-04-23
太长不看(TL;DR) —
gpt-image-2是 OpenAI 目前的旗舰图像模型。真正的亮点不在于“更漂亮的图片”,而是图像生成终于跨越了情绪板素材的界限,成为了真正可以交付给用户的生产级视觉输出。
核心亮点
gpt-image-2 绝非一次小幅更新。它是 OpenAI 目前定位为所有涉及图像生成或编辑的新工作流的默认模型。以下四大升级最为关键:
- 可靠的文本渲染 — 海报、信息图表、漫画分镜、多语言宣传图。
- 稳定的编辑能力 — 参考图像、角色一致性、蒙版编辑、迭代优化。
- 结构化布局 — 信息图表、图表、多面板漫画,而不再局限于单一的主视觉图。
- 融合世界知识的逼真度 — 输出的图像看起来像真实物品,并置于真实的场景中。
如果你正在开发 SaaS 产品、设计工具、内容平台、电商商店、品牌工作流,或任何需要可编辑图像输出的项目,这相比之前的模型是一个意义重大的飞跃。
它究竟是什么
OpenAI 于 2026 年 4 月 21 日推出了 ChatGPT Images 2.0 — 他们的新一代图像模型,内部代号为 gpt-image-2。它的定位非常明确:
- 未来默认的 GPT 图像模型
- 集文本生成图像(文生图)与图像编辑于一体的单一模型
- 支持文本和图像双重输入
- 输出图像
- 核心优势:高质量生成、可靠的编辑、强大的指令遵循能力、复杂布局、图像内文本、逼真度以及世界知识
究竟有哪些新特性

1. 文本生成图像(Text-to-image)
这是基础能力。但 gpt-image-2 的意义不在于“它会画画”,而在于可控的绘画。OpenAI 的文档描述了其强大的指令遵循能力以及基于广博世界知识的上下文感知能力。
在实际应用中,它非常适合:
- 品牌主视觉图、横幅(Banners)、OG 图像
- 宣传海报
- 文章插图
- UI 概念设计图
- 角色设计表
- 教学说明插图
- 电商与营销资产
2. 图像编辑
这才是真正取得突破的地方。官方文档反复强调了其在两种常见模式下的编辑性能:
- 全图编辑 — 输入一张图像,并通过提示词(Prompt)改变其风格、材质、构图或内容
- 蒙版编辑 — 仅修改选定区域,同时保留其他所有内容
真正实用的应用场景包括:
- 基于参考图的变体生成
- 局部重绘
- 面部与角色一致性
- 批量(Batch)调整品牌资产
- 电商:替换产品、背景、道具
- 在现有艺术作品上迭代,而不是从头重新生成
3. 图像内文本与排版
这是最大的能力解锁。OpenAI 的提示词指南特别提到了可靠的文本渲染,包括清晰的字母、一致的布局和强烈的对比度。
这改变了游戏规则。“AI 图像无法处理文本”曾是区分情绪板和成品资产的一道硬性界限。有了 gpt-image-2,以下场景突然变得可行:
- 活动海报
- 信息图表
- 多语言宣传图
- 菜单、封面、传单、贴纸
- 带有对话的漫画分镜
- 教育图表与流程图
- 社交媒体模板
4. 结构化与多面板内容
文档明确将能力扩展至:
- 信息图表
- 图表
- 多面板构图
换句话说,它不再仅仅是“一张漂亮的图片”。它开始能够处理结构化的视觉输出——这对于任何开发内容、教育或营销自动化产品的人来说都是一件大事。
5. 风格控制与迁移
提示词指南强调了:
- 精确的风格控制
- 极简提示词下的风格迁移
适用于:
- 统一的品牌视觉
- 色调一致的系列图像
- 基于参考图的风格迁移
- 在插画、漫画、像素、摄影和海报风格之间无缝切换
- 跨场景的角色一致性
6. 世界知识与场景理解
系统卡片(System Card)强调了在世界知识、指令遵循和密集文本渲染方面的显著提升。这对于以下方面至关重要:
- 逼真的产品植入
- 旅游、餐饮和零售营销
- 具备行业特定准确性的概念设计图
- 基于真实世界语境的商业视觉
它在实际产品中的真实表现
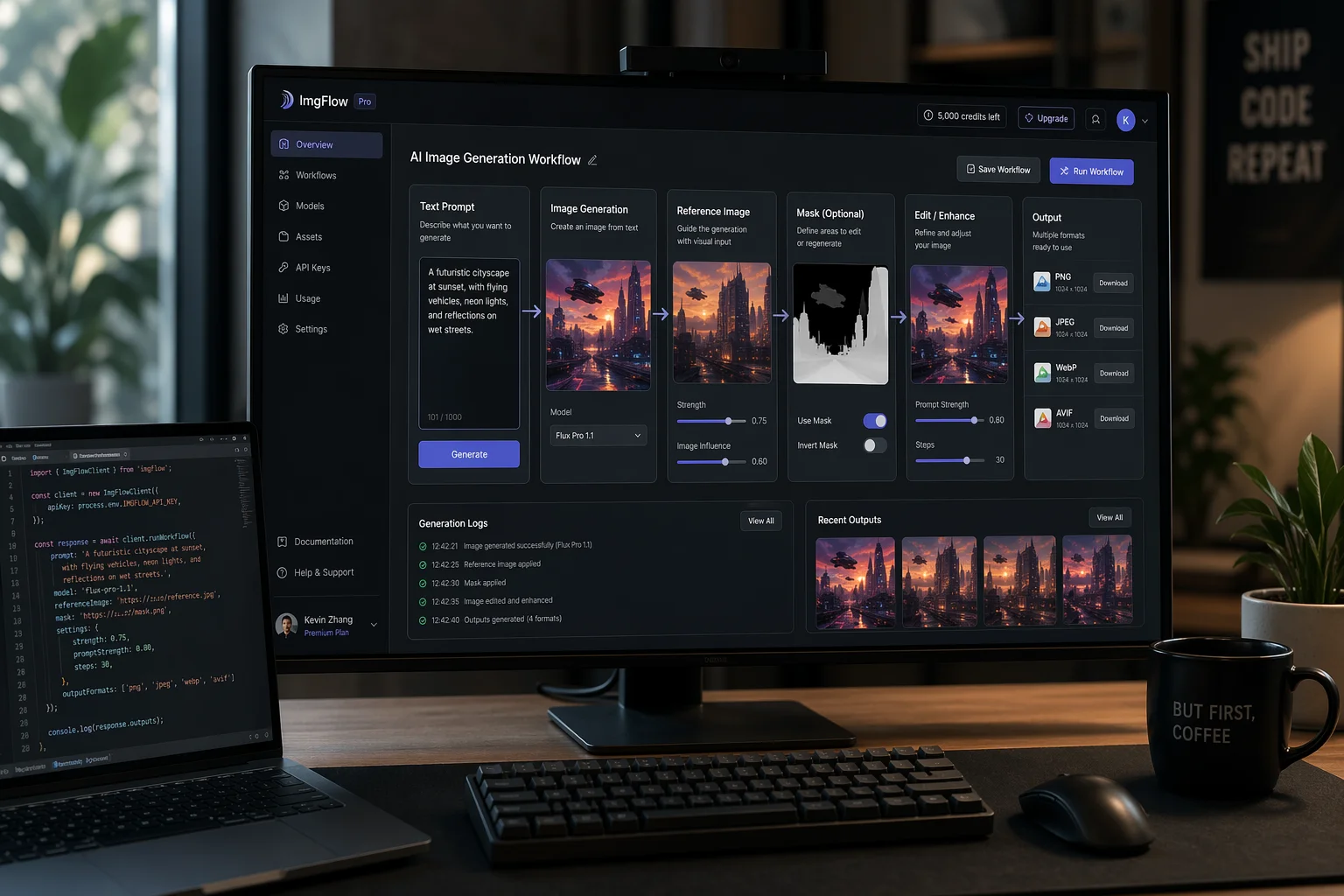
纸面上的能力是一回事。模型能否支撑起面向用户的真实工作流则是另一回事。我们最近在 PicFixer 上推出的两款工具,正是得益于这一代模型解锁的能力——这两款工具在旧版图像模型上基本是无法实现的。
漫画翻译器 (Manga Translator)
翻译漫画页面实际上并不是一个翻译问题,而是一个文本渲染问题。旧版 AI 图像模型无法在分镜内写出干净、排版良好的文本,更不用说在将日语替换为英语时保留原始布局、对话框形状和漫画美感了。
借助 gpt-image-2,我们可以:
- 检测并替换对话框内的文本
- 保留分镜构图和周围的艺术画面
- 使排版与漫画的视觉语言相匹配
- 在单一工作流中支持多种目标语言
上一代模型的输出往往是扭曲、变形或几乎无法辨认的。而这一代模型首次实现了真正可读的输出结果。
立即体验 → picfixer.ai/tools/manga-translator
AI 室内设计 (AI Interior Design)
仅凭一张照片重新设计房间,这正是旧版模型根本无法做好的事情。它们会产生不可能的几何幻觉,破坏门窗布局,或者生成毫无真实感、充满“AI 味”的通用家具。
gpt-image-2 结合了高保真参考图处理、世界知识和逼真度,使我们能够:
- 保留房间的真实建筑结构
- 在保持空间完整的同时切换风格(北欧风、工业风、侘寂风、世纪中叶现代风等)
- 生成看起来像真实可购买的家具
- 在同一张照片上围绕多个设计方向进行迭代
立即体验 → picfixer.ai/tools/ai-interior-design
这两款工具都建立在同一个底层转变之上:AI 图像模型不再是情绪板生成器。它们正在成为生产组件。
它的最大价值在哪里
gpt-image-2 具有明显优势的八大产品类别:
- AI 海报与营销资产生成
- 文章插图与信息图表
- 电商产品编辑与场景变体
- 品牌视觉资产生成
- 具备多图一致性的角色设计
- 基于参考图的创意编辑
- 教育图表、流程图、讲解视觉图
- 多轮交互式设计助手
当你的工作流有以下任何需求时,这种优势会成倍增加:
- 图像内包含文本
- 多语言输出
- 局部编辑
- 一致的角色或物体
- 多次迭代
- 生产级输出,而不仅仅是寻找灵感的静态图
我的解读
如果必须用一句话来概括:
gpt-image-2已经明确从“AI 图像模型”进化为“能够融入生产管线的图像生成与编辑模型”。
它的价值不在于单张图片看起来更令人惊艳,而在于:
- 首次尝试的成功率更高
- 编辑工作流足够稳定,可以投入实际应用
- 文本和布局终于可用了
- 它能融入实际产品,而不仅仅是演示(Demos)
- 迭代式的多步工作流变得真正有意义
对于任何将图像作为实际输出(而非仅仅是营销噱头)的产品开发者来说,这一代 AI 图像生成开始让人觉得不再是一个新奇玩具,而是一个你可以赖以构建产品的视觉引擎。上述两款工具就是小小的证明:那些在上一代模型中根本无法实现的产品类别,现在已经可以正式发布了。