GPT-Image-2 : Ce que le dernier modèle d'image d'OpenAI change vraiment
Par l'équipe de recherche de PicFixer.ai | Avril 2026
GPT-Image-2 : Ce que le dernier modèle d'image d'OpenAI change vraiment

Mis à jour le : 2026-04-23
En bref —
gpt-image-2est l'actuel modèle d'image phare d'OpenAI. La véritable avancée n'est pas de faire de "plus jolies images". C'est que la génération d'images a enfin franchi le cap, passant de simple planche de tendance à une production visuelle de qualité professionnelle que vous pouvez réellement proposer à vos utilisateurs.
L'essentiel
gpt-image-2 n'est pas une simple mise à jour mineure. C'est le modèle qu'OpenAI positionne désormais comme la référence par défaut pour tout nouveau projet impliquant la génération ou l'édition d'images. Quatre améliorations se démarquent particulièrement :
- Rendu de texte fiable — affiches, infographies, cases de bande dessinée, visuels promotionnels multilingues.
- Édition stable — images de référence, cohérence des personnages, retouches par masque, affinement itératif.
- Mises en page structurées — infographies, diagrammes, bandes dessinées à plusieurs cases, et plus seulement des images uniques.
- Photoréalisme et connaissance du monde — des résultats qui ressemblent à des objets réels, placés dans des contextes réels.
Si vous développez un SaaS, un outil de design, une plateforme de contenu, une boutique e-commerce, un flux de travail de marque ou tout autre projet nécessitant des images éditables, il s'agit d'une avancée significative par rapport aux modèles précédents.
De quoi s'agit-il exactement ?
OpenAI a lancé ChatGPT Images 2.0 le 21 avril 2026 — leur modèle d'image de nouvelle génération, nommé en interne gpt-image-2. Son positionnement est clair :
- Le modèle GPT Image par défaut pour l'avenir
- Text-to-image et édition d'images réunis dans un seul modèle
- Accepte les entrées sous forme de texte et d'image
- Produit des images en sortie
- Objectifs : génération de haute qualité, édition fiable, respect strict des instructions, mises en page complexes, texte intégré à l'image, photoréalisme et connaissance du monde
Ce qui est vraiment nouveau

1. Text-to-image
La base. Mais l'intérêt de gpt-image-2 n'est pas simplement de "savoir peindre" — c'est de peindre de manière contrôlable. La documentation d'OpenAI décrit un respect rigoureux des instructions et une conscience contextuelle fondée sur une vaste connaissance du monde.
En pratique, il est parfaitement adapté pour :
- Les visuels clés de marque, les bannières, les images Open Graph (OG)
- Les affiches promotionnelles
- Les illustrations d'articles
- Les concepts d'interface utilisateur (UI)
- Les planches de conception de personnages
- Les illustrations pédagogiques
- Les ressources e-commerce et marketing
2. Édition d'images
C'est ici que les véritables progrès se font sentir. La documentation souligne à plusieurs reprises les performances d'édition, selon deux modèles courants :
- Édition de l'image entière — fournissez une image et demandez une modification du style, de la texture, de la composition ou du contenu
- Édition par masque — modifiez uniquement une zone sélectionnée tout en préservant le reste
Ce qui devient véritablement utile :
- Les variations basées sur des références
- Les retouches locales (repainting)
- La cohérence des visages et des personnages
- Les ajustements en lot des ressources de marque
- E-commerce : le remplacement de produits, d'arrière-plans et d'accessoires
- L'itération sur des créations existantes au lieu de tout regénérer depuis zéro
3. Texte intégré à l'image et typographie
C'est la plus grande avancée. Le guide de prompt d'OpenAI mentionne spécifiquement un rendu de texte fiable avec un lettrage net, une mise en page cohérente et un fort contraste.
Cela change la donne. "L'IA ne sait pas faire de texte" était autrefois la frontière stricte entre les planches de tendance et les ressources finalisées. Avec gpt-image-2, les éléments suivants deviennent soudainement réalisables :
- Les affiches d'événements
- Les infographies
- Les visuels promotionnels multilingues
- Les menus, couvertures, flyers, autocollants
- Les cases de bande dessinée avec dialogues
- Les diagrammes et organigrammes éducatifs
- Les modèles pour les réseaux sociaux
4. Contenu structuré et à plusieurs panneaux
La documentation étend explicitement cette capacité aux :
- Infographies
- Diagrammes
- Compositions à plusieurs panneaux (cases)
En d'autres termes, il ne s'agit plus seulement d'"une belle image". Le modèle commence à gérer des sorties visuelles structurées — une avancée majeure pour quiconque développe des produits de contenu, d'éducation ou d'automatisation marketing.
5. Contrôle et transfert de style
Le guide de prompt met en évidence :
- Un contrôle précis du style
- Le transfert de style avec un minimum de prompt
Utile pour :
- L'unification des visuels de marque
- Les séries d'images au ton cohérent
- Le transfert de style à partir d'une image de référence
- Le passage entre les styles illustration, bande dessinée, pixel art, photographie et affiche
- La cohérence des personnages à travers différentes scènes
6. Connaissance du monde et compréhension des scènes
La fiche système (system card) souligne des gains substantiels en matière de connaissance du monde, de respect des instructions et de rendu de texte dense. Cela est crucial pour :
- Le placement de produit réaliste
- Le marketing dans les secteurs du voyage, de l'alimentation et de la vente au détail
- Les concepts artistiques avec une précision spécifique à l'industrie
- Les visuels commerciaux ancrés dans un contexte réel
Comment cela se traduit dans des produits réels
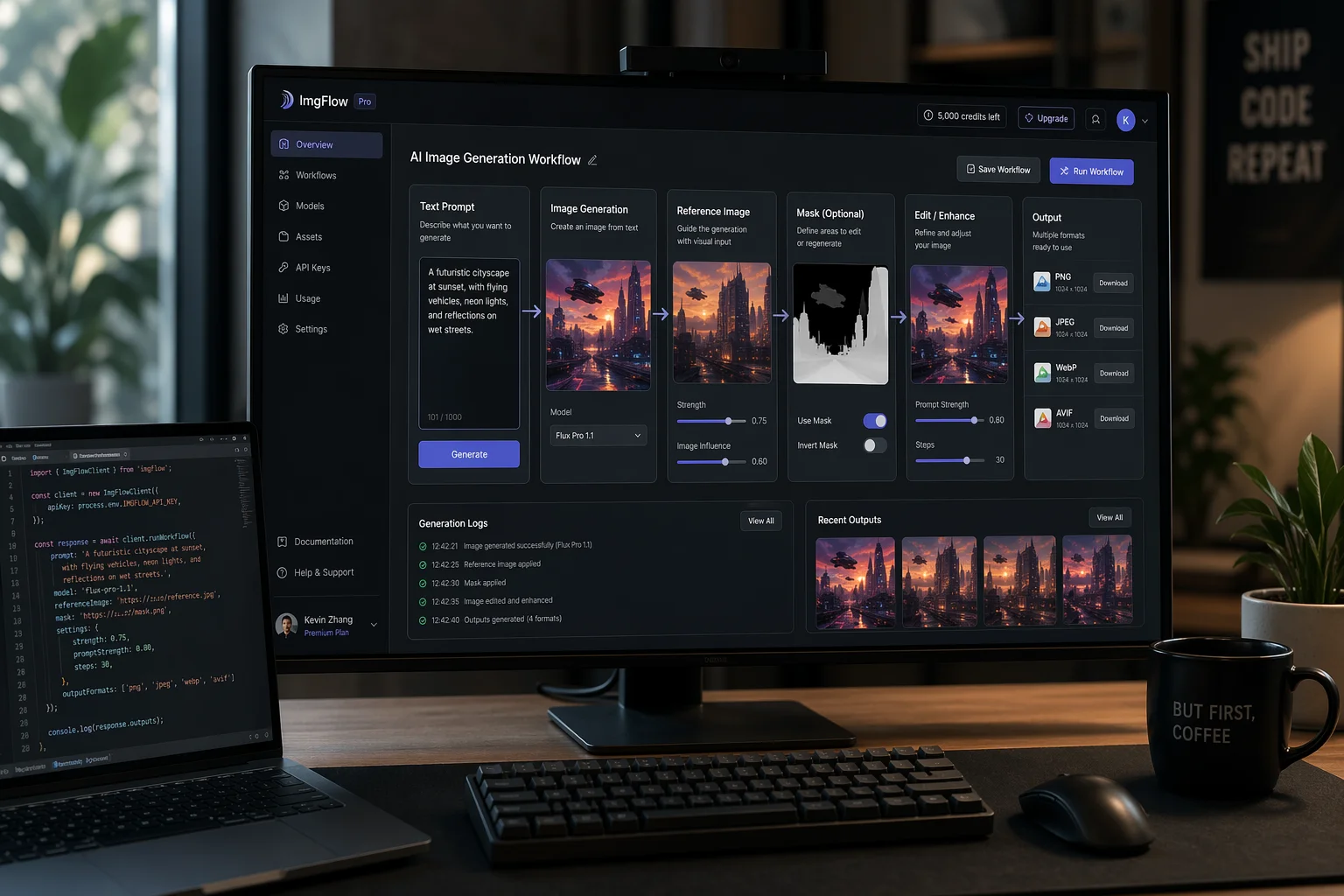
Les capacités sur le papier sont une chose. Savoir si un modèle peut supporter de véritables flux de travail orientés utilisateur en est une autre. Deux outils que nous avons récemment lancés sur PicFixer ne sont possibles que grâce à ce que cette génération débloque — tous deux étaient pratiquement impossibles à déployer avec les anciens modèles d'image.
Manga Translator
Traduire une page de manga n'est pas vraiment un problème de traduction — c'est un problème de rendu de texte. Les anciens modèles d'image IA ne pouvaient pas écrire un texte propre et typographié à l'intérieur d'une case, et encore moins préserver la mise en page originale, la forme des bulles et l'esthétique de la bande dessinée tout en remplaçant le japonais par l'anglais.
Avec gpt-image-2, nous pouvons :
- Détecter et remplacer le texte à l'intérieur des bulles
- Préserver la composition des cases et les dessins environnants
- Adapter la typographie au langage visuel de la bande dessinée
- Prendre en charge plusieurs langues cibles dans un seul flux de travail
Les résultats de la génération précédente étaient déformés, altérés ou à peine lisibles. Cette génération est la première où le résultat est véritablement lisible.
Essayez-le → picfixer.ai/tools/manga-translator
AI Interior Design
Repenser le design d'une pièce à partir d'une seule photo est typiquement le genre de chose que les anciens modèles ne parvenaient pas à bien faire. Ils hallucinaient des géométries impossibles, cassaient la disposition des fenêtres et des portes, ou produisaient des meubles génériques "typés IA" sans aucun rapport avec la réalité.
La combinaison de la gestion de références haute fidélité, de la connaissance du monde et du photoréalisme de gpt-image-2 nous permet de :
- Préserver l'architecture réelle de la pièce
- Changer de style (scandinave, industriel, Japandi, mid-century) tout en gardant l'espace intact
- Générer des meubles qui ressemblent à des articles que vous pourriez réellement acheter
- Itérer sur une seule photo à travers de multiples directions de design
Essayez-le → picfixer.ai/tools/ai-interior-design
Ces deux outils reposent sur le même changement fondamental : les modèles d'image IA ne sont plus de simples générateurs de planches de tendance. Ils deviennent de véritables composants de production.
Là où il apporte le plus de valeur
Les huit catégories de produits pour lesquelles gpt-image-2 est un atout indéniable :
- Génération d'affiches et de ressources marketing par l'IA
- Illustration d'articles et infographies
- Édition de produits e-commerce et variantes de scènes
- Génération de ressources visuelles de marque
- Conception de personnages avec cohérence multi-images
- Édition créative basée sur des références
- Diagrammes éducatifs, organigrammes, visuels explicatifs
- Assistants de design interactifs à tours multiples
Les avantages se multiplient lorsque votre flux de travail présente l'un de ces besoins :
- Du texte à l'intérieur de l'image
- Des résultats multilingues
- Des retouches locales
- Des personnages ou objets cohérents
- De multiples itérations
- Des résultats de qualité professionnelle, et pas seulement des images d'inspiration
Mon analyse
Si je devais résumer en une phrase :
gpt-image-2a clairement évolué du statut de "modèle d'image IA" à celui de "modèle de génération et d'édition d'images qui s'intègre dans les pipelines de production."
La valeur ajoutée ne réside pas dans le fait que les images individuelles soient plus impressionnantes. C'est plutôt que :
- Le taux de réussite dès la première tentative est plus élevé
- Les flux de travail d'édition sont suffisamment stables pour être déployés
- Le texte et la mise en page fonctionnent enfin
- Il s'intègre dans de vrais produits, pas seulement dans des démos
- Les flux de travail itératifs à plusieurs étapes prennent tout leur sens
Pour quiconque développe un produit dont les images sont un véritable résultat — et non un simple artifice marketing — c'est la génération où la création d'images par l'IA commence à ressembler moins à une nouveauté et davantage à un moteur visuel sur lequel vous pouvez vous appuyer. Les deux outils mentionnés ci-dessus en sont de petites preuves : des catégories qui n'étaient tout simplement pas viables avec la génération de modèles précédente peuvent désormais être lancées sur le marché.